
প্রতিদিন একটা গবেষণাপত্র পড়ার আজ অষ্টম দিন। NLP নিয়ে কাজ যে কত দ্রুত এগিয়ে যাচ্ছে এই গবেষণা তার প্রমাণ। আজকের সময় আমরা কখনোই user এর দেওয়া prompt সরাসরি AI কে দিয়ে দেই না। এর সাথে অনেক রকম তথ্য জুড়ে দেই যেন AI সঠিকভাবে বুঝতে পারে কি করতে হবে। এর অনেক রকম পদ্ধতি আছে। সবচেয়ে প্রচলিত একটা পদ্ধতি হল RAG. তো এই পেপারটা এরকমই একটা পদ্ধতি নিয়ে আলাপ করেছে ২০২৩ সালে।
আপনি এআইকে একটা খুব জটিল প্রশ্ন করলেন। যেমন, "জাভা দিয়ে তৈরি করা সবচেয়ে নতুন কম্পিউটার ইমুলেটরের নাম কী?" এআই কীভাবে এই উত্তরটা খুঁজে বের করে?
সাধারণত, এআই মডেলগুলো এই প্রশ্নের জবাবে একটা জটিল প্রোগ্রাম বা কোড নিজে নিজে 'তৈরি' বা জেনারেট করার চেষ্টা করে। কিন্তু এই চেষ্টা করতে গিয়ে তারা প্রায়ই ভুল করে ফেলে। এমন কোড লিখে ফেলে যা আসলে কোনো কাজেরই না, অথবা সিনট্যাক্স ভুল, কিংবা যা চাওয়া হয়েছে তার সাথে কোনো সম্পর্কই নেই। জিপিটি তে কাজ নাই কাম নাই হটাত করে 'Analyzing' লেখা উঠে যা চাই নাই তাও দিয়ে দেওয়ার একটা প্রবণতা যে কিছুদিন আগেও ছিল তা আমরা সবাই দেখেছি।
ঠিক এই জায়গাতেই ২০২৩ সালে এই গবেষণাপত্র প্রকাশ হয়। পেপারটির জন্য গবেষকরা এসিএল ২০২৩ সম্মেলনে আউটস্ট্যান্ডিং পেপার অ্যাওয়ার্ড পান, যা হাজার হাজার পেপারের মধ্যে সেরা বলে বিবেচিত হয়। পেপারটার নামটাই খুব মজার: "ডোন্ট জেনারেট, ডিসক্রিমিনেট", বাংলায় বললে দাঁড়ায়, "নিজের বানাইতে যাইয়োনা বাবা, বরং খুঁজে নাও কোনটা লাগবে।"
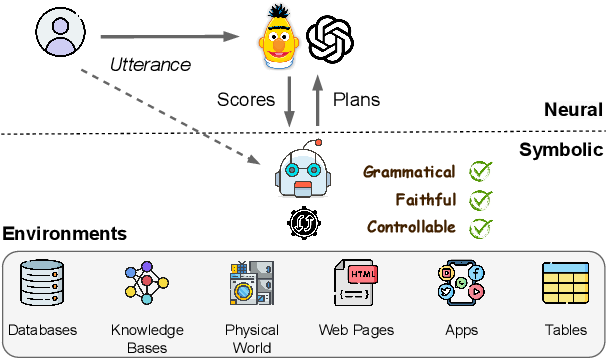
এই পেপারের মূল ধারণাটা খুব সহজ কিন্তু যুগান্তকারী। গবেষকরা বললেন, এআইকে দিয়ে কেন আমরা শূন্য থেকে একটা জটিল প্রোগ্রাম তৈরি করানোর চেষ্টা করছি? এটা তো ওর কাজ না। তার চেয়ে বরং আমরা ওকে শুধু বাছাই করতে শেখাই।
তারা 'PANGU' নামে একটা নতুন সিস্টেম তৈরি করেছেন। এই সিস্টেমটা prompt পেলেই নিজে সবটা তৈরি করে না। এর দুইটা প্রধান অংশ আছে। একটা হলো 'হেল্পার' এজেন্ট, আরেকটা হলো 'মস্তিষ্ক' বা ল্যাঙ্গুয়েজ মডেল।
আসুন ধাপে ধাপে দেখি এটা কীভাবে কাজ করে।
ধরুন, সেই আগের প্রশ্নটাই করা হলো: "জাভা দিয়ে তৈরি লেটেস্ট কম্পিউটার ইমুলেটর কোনটা?"
ধাপ ১: প্রশ্ন পাওয়ার পর প্রথমে 'হেল্পার' এজেন্ট ডেটাবেস বা জ্ঞানের ভাণ্ডার ঘেঁটে দেখে। সে 'জাভা' শব্দটার সাথে কী কী সম্পর্ক থাকতে পারে তার একটা তালিকা বানায়। যেমন:
(ক) জাভার সাথে সম্পর্কিত ভাষা,
(খ) জাভার মাধ্যমে তৈরি সফটওয়্যার,
(গ) জাভার ইতিহাস।
গুরুত্বপূর্ণ বিষয় হলো, হেল্পার এজেন্ট কখনোই কোনো ভুল বা আজগুবি রাস্তা দেখায় না, শুধু যেগুলো ডেটাবেসে আসলেই সম্ভব, সেগুলোই দেখায়।
ধাপ ২: এবার 'মস্তিষ্ক' মানে মূল এআই মডেলের কাজ শুরু। সে প্রশ্নটা খুব মন দিয়ে পড়ে। তারপর হেল্পারের দেওয়া তিনটা রাস্তার মধ্যে 'বাছাই' বা ডিসক্রিমিনেট করে। সে বোঝে যে, যেহেতু প্রশ্নটা 'ইমুলেটর' বা সফটওয়্যার নিয়ে, তাই (খ) 'জাভার মাধ্যমে তৈরি সফটওয়্যার' রাস্তাটাই সবচেয়ে ঠিক। সে ওটাকে বেছে নেয়।
ধাপ ৩: প্রথম ধাপ ঠিকঠাক পার হওয়ার পর, হেল্পার এজেন্ট আবার নতুন কিছু রাস্তা দেখায়। সে 'জাভার মাধ্যমে তৈরি সফটওয়্যার' গুলোর মধ্যে কী কী করা সম্ভব তা খুঁজে বের করে। যেমন:
(ক) সফটওয়্যারগুলোর ধরন (যেমন কম্পিউটার ইমুলেটর),
(খ) সফটওয়্যারগুলোর ডেভেলপার,
(গ) সফটওয়্যারগুলোর লাইসেন্স।
ধাপ ৪: 'মস্তিষ্ক' আবার প্রশ্নটা দেখে এবং এই নতুন অপশনগুলো থেকে সঠিকটা বাছাই করে। সে বেছে নেয় (ক) 'কম্পিউটার ইমুলেটর'।
ধাপ ৫: এভাবে ধাপে ধাপে শুধু সঠিক রাস্তাগুলো বাছাই করতে করতে এআই একেবারে শেষ উত্তরের দিকে এগোতে থাকে। পরের ধাপে সে হয়তো 'রিলিজ ডেট' বাছাই করে এবং সবশেষে 'লেটেস্ট' বা 'সবচেয়ে নতুন' ফাংশনটা বাছাই করে। ব্যস! উত্তর তৈরি।
পুরনো সিস্টেমগুলো যেখানে শূন্য থেকে একটা বড় কোড লেখার চেষ্টা করে ফেল হতো, এই সিস্টেমটা সেখানে অনেকটা গুপ্তধন খোঁজার মত প্রত্যেক ধাপে পাওয়া তথ্য গুলো নিয়ে ফেলু মিত্তির হয়ে ওঠে আর রহস্য সমাধান করার মতই প্রশ্নের আর সম্ভাবনার ট্রেস খুঁজতে খুঁজতে সঠিক উত্তরে পৌঁছে যায়।
তো, এই নতুন পদ্ধতিতে লাভটা কী হলো?
ফলাফল ছিল অসাধারণ। গবেষকরা যখন এই সিস্টেমকে খুব জটিল সব প্রশ্নোত্তরের ডেটাসেটে পরীক্ষা করলেন, এটা আগের সব রেকর্ড ভেঙে দিলো। বিশেষ করে একটা খুব কঠিন ডেটাসেটে এটা আগের সেরা সিস্টেমের চেয়ে প্রায় দ্বিগুণ ভালো ফল করেছে।
তবে সবচেয়ে অবাক করা বিষয় হলো এর শেখার ক্ষমতা। পুরনো মডেলগুলোকে একটা কাজ শেখানোর জন্য হাজার হাজার উদাহরণ বা ডেটা দিতে হতো। কিন্তু এই নতুন সিস্টেমকে মাত্র একটা বা দশটা উদাহরণ দেখিয়েই ছেড়ে দেওয়া গেছে। এবং তাতেই সে অসাধারণ নির্ভুলভাবে কাজ করেছে। মাত্র একটা উদাহরণ দেখে সে ৫০ শতাংশের বেশি সঠিক উত্তর দিতে পেরেছে, যা এককথায় অবিশ্বাস্য। এর মানে হলো, এই সিস্টেমকে নতুন কোনো কাজে লাগানোর জন্য খুব বেশি ডেটার দরকার হয় না।
তবে সব ভালো জিনিসেরই কিছু দুর্বলতা থাকে। গবেষকরা সততার সাথে সেটাও বলেছেন।
প্রথমত, এই সিস্টেমটা বেশ ধীরগতির। কারণ তাকে প্রতি ধাপে অনেকগুলো অপশন ঘেঁটে ঘেঁটে দেখতে হয়, তাই সময় আর কম্পিউটিং ক্ষমতা দুটোই বেশি লাগে। পুরনো সিস্টেমগুলো হয়তো ভুল করতো, কিন্তু কাজ করতো অনেক দ্রুত।
দ্বিতীয়ত, এটাকে ঠিকভাবে শেখানোর জন্য একদম নিখুঁত 'সঠিক উত্তর' বা 'গোল্ড প্ল্যান' দরকার হয়। এই ধরনের নিখুঁত ডেটা তৈরি করা খুব খরচসাপেক্ষ এবং সময়সাপেক্ষ ব্যাপার।
সব মিলিয়ে, এই পেপারটা এআইকে ভাষা বোঝানোর একটা নতুন রাস্তা খুলে দিয়েছে। এটা দেখিয়েছে যে, এআইকে দিয়ে সবটা 'তৈরি' করানোর বদলে যদি তাকে শুধু ঠিক জিনিসটা 'বাছাই' করতে শেখানো যায়, তবে সে অনেক কম ডেটা নিয়েও অনেক বেশি নির্ভুলভাবে কাজ করতে পারে।