
আপনি যখন কিছু একটা সার্চ করেন, ধরেন লিখলেন,
"ঢাকার সেরা কাচ্চি"
গুগল ঠিকঠাক বুঝে ফেলে আপনাকে রেস্টুরেন্টের লিস্ট দেখায়। কিংবা, আপনি ফেসবুকে কিছু একটা লিখছেন, আপনার মোবাইল কিবোর্ড পরের শব্দটি কী হবে তা আন্দাজ করে ফেলে।
সত্যি বলতে, কম্পিউটার তো আসলে আমাদের বাংলা বা ইংরেজি ভাষা বোঝে না।
কম্পিউটার বোঝে শুধু সংখ্যা শূন্য আর এক।
তাহলে এই বোকা যন্ত্রটা কীভাবে নজরুলের কবিতা বা আপনার আমার চ্যাটিং-এর ভাষা বোঝে?
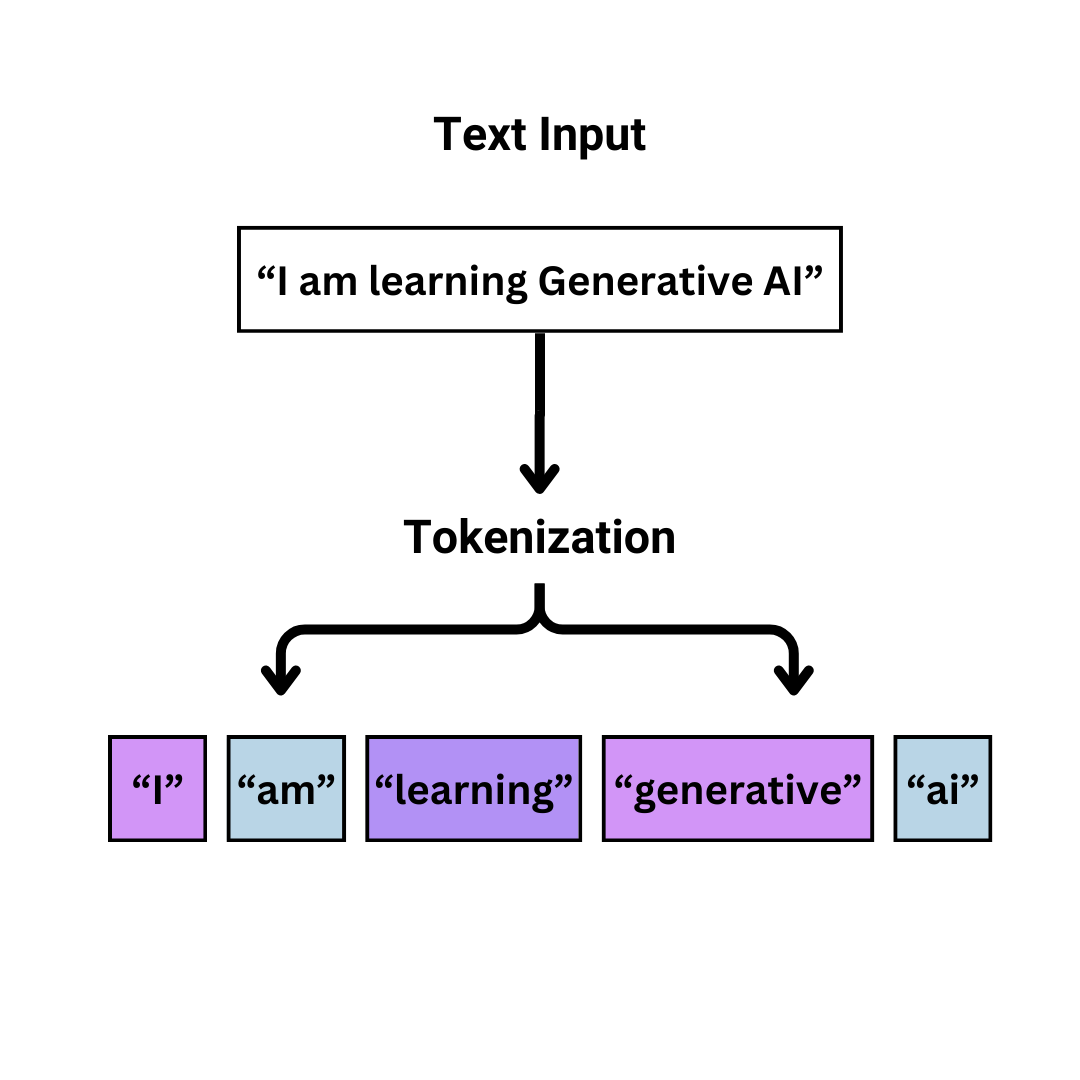
এই পুরো বিষয়ের প্রথম ধাপ, এবং সম্ভবত সবচেয়ে গুরুত্বপূর্ণ ধাপটির নাম হলো "টোকেনাইজেশন" (Tokenization)।
টোকেনাইজেশন কী?
শব্দটা শুনে কঠিন মনে হলেও, কাজটা খুব সোজা।
টোকেনাইজেশন মানে হলো, একটা বড় বাক্যকে ছোট ছোট যৌক্তিক অংশে বা "টুকরোতে" ভাগ করা। এই প্রত্যেকটা টুকরোকে বলা হয় "টোকেন"।
ভাবছেন, এ আর এমন কী? একটা বাক্যকে শব্দে শব্দে আলাদা করা?
আসেন, একটা সহজ উদাহরণ দেখি।
বাক্য: "আমি ভাত খাই।"
একটা বাচ্চা ছেলেও এটাকে ভাগ করে ফেলবে:
- টোকেন ১: "আমি"
- টোকেন ২: "ভাত"
- টোকেন ৩: "খাই"
- টোকেন ৪: "।" (দাঁড়ি)
খুব সোজা। কম্পিউটার এই চারটি আলাদা টোকেন পেল। সে এই প্রতিটি টোকেনকে একটা একটা করে সংখ্যা দিয়ে চিনে রাখে।
যেমন, ধরা যাক তার ডিকশনারিতে:
- "আমি" → ৫০
- "ভাত" → ২০১
- "খাই" → ৩৫০
- "।" → ৪
সে বাক্যটাকে দেখবে এভাবে: [৫০, ২০১, ৩৫০, ৪]
ব্যাস! বাক্যটা সংখ্যায় বদলে গেলো। কম্পিউটারের বুঝতে সুবিধা হলো।
কিন্তু... জীবন এতো সহজ নয়।
এই সোজা কাজটা করতে গেলেই পদে পদে বিপদ।
বিপদ ১: যতিচিহ্ন
ধরুন বাক্যটা হলো "আমি ভাত খাই!"
এখন শেষ টোকেনটা কি "খাই!" নাকি "খাই" আর "!" আলাদা?
যদি "খাই!" কে একটা টোকেন ধরা হয়, তাহলে কম্পিউটারের ডিকশনারিতে "খাই" এবং "খাই!" দুটো আলাদা শব্দ হয়ে গেলো। অথচ দুটোর মানে তো একই। আবার যদি "!" কে আলাদা করা হয়, তাহলে কম্পিউটার বুঝবে যে এটা একটা আশ্চর্যবোধক বাক্য। টোকেনাইজেশন ঠিকঠাক না হলে, কম্পিউটার বাক্যের আবেগই ধরতে পারবে না।
বিপদ ২: ইংরেজি নাম বা জোড়া শব্দ
ধরুন আপনি লিখলেন "আমি নিউ ইয়র্ক যাবো।"
যদি স্পেস দেখে ভাগ করা হয়, তাহলে টোকেন হবে:
- "আমি"
- "নিউ"
- "ইয়র্ক"
- "যাবো"
- "।"
এতে একটা মস্ত বড় ভুল হলো। "নিউ" আর "ইয়র্ক" আলাদা শব্দ নয়। এটা একটা জায়গার নাম "নিউ ইয়র্ক"। কম্পিউটার যদি "নিউ" কে 'নতুন' আর "ইয়র্ক" কে আলাদা কিছু ভাবে, তাহলে সে ভাববে "আমি নতুন ইয়র্ক যাবো", যার কোনো মানে হয় না।
সঠিক টোকেনাইজেশন হবে:
- "আমি"
- "নিউ ইয়র্ক"
- "যাবো"
- "।"
অর্থাৎ, সিস্টেমকে বুঝতে হবে যে "নিউ ইয়র্ক" একটা জিনিস।
বিপদ ৩: বাংলা যুক্তশব্দ (সবচেয়ে বড় বিপদ)
ভাষার আসল মজা শুরু হয় এখানে।
ধরুন একটা শব্দ: "প্রধানমন্ত্রীর" এটা কি একটা টোকেন? নাকি "প্রধান" আর "মন্ত্রীর" দুটো টোকেন?
যদি একটা টোকেন হয়, তাহলে ঠিক আছে।
কিন্তু যদি কম্পিউটার "প্রধানমন্ত্রী" শব্দটা আগে কখনো না দেখে? সে তো বুঝতেই পারবে না এর মানে কী।
আবার ধরুন, "চা-ওয়ালা" বা "টাউনহল"। এগুলো কীভাবে ভাঙবে?
বিপদ ৪: অসীম শব্দভাণ্ডার
পৃথিবীতে শব্দের সংখ্যা অসীম। প্রতিদিন নতুন শব্দ তৈরি হচ্ছে, "কোভিড১৯", "ইনস্টাগ্রামিং", "ট্রলড"। আবার বাংলা ভাষায় ক্রিয়াপদের হাজারটা রূপ:
- "খেয়েছিলাম"
- "খাচ্ছিলাম"
- "খাবো"
- "খেতে"
- "খাইয়ে"।
একটা কম্পিউটারের ডিকশনারিতে কত কোটি শব্দ সেভ করে রাখা সম্ভব?
শত শত কোটি? তাও তো শেষ হবে না।
সমাধান: সাবওয়ার্ড টোকেনাইজেশন (Subword Tokenization)
এই সমস্যার সমাধানের জন্য বিজ্ঞানীরা এক দারুণ বুদ্ধি বের করলেন। একে বলা হয় "সাবওয়ার্ড টোকেনাইজেশন"।
ব্যাপারটা একটা লেগো (Lego) ব্লকের খেলার মতো।
ধরুন, আপনার কাছে মাত্র ৫০০ রকমের ব্লক আছে। কিন্তু এই ৫০০ ব্লক দিয়েই আপনি দুনিয়ার সব কিছু বানাতে পারেন। একটা গাড়ি বানাতেও যে ব্লক লাগে, একটা বাড়ি বানাতেও সেই একই ব্লক লাগে, শুধু জোড়া লাগানোর কৌশলটা ভিন্ন।
ভাষার লেগো ব্লক
ভাষার ক্ষেত্রেও এই বুদ্ধি খাটানো হলো।
ঠিক করা হলো, আমরা পুরো শব্দকে টোকেন বানাবো না আমরা শব্দের "ভেতরের অংশ" কে টোকেন বানাবো।
যেমন:
- "খেয়েছিলাম" → "খেয়ে" + "ছিলাম"
- "খাচ্ছিলাম" → "খা" + "চ্ছিলাম"
- "অসম্ভব" → "অ" + "সম্ভব"
দেখুন মজাটা! "ছিলাম" বা "চ্ছিলাম" বা "অ" এগুলো নিজেরা কোনো শব্দ নয়, কিন্তু এগুলো বারবার অন্য শব্দের সাথে যুক্ত হয়।
কম্পিউটার যদি "খেয়ে" আর "ছিলাম" এর মানে আলাদা করে শিখে ফেলে, তাহলে সে "গিয়েছিলাম" (গিয়ে + ছিলাম) বা "দেখেছিলাম" (দেখে + ছিলাম) শব্দগুলোও সহজে চিনে ফেলবে এমনকি যদি সে শব্দগুলো আগে কখনো নাও দেখে থাকে।
এই সাবওয়ার্ড বা "শব্দাংশ" গুলোই হলো আসল লেগো ব্লক।
আধুনিক সিস্টেমে টোকেনাইজেশন
আধুনিক সিস্টেমগুলো (যেমন GPT বা Google Translate) এভাবেই কাজ করে।
তারা আপনার বাক্যকে শব্দে নয়, শব্দাংশে ভাঙে।
ধরুন, একটা নতুন শব্দ আসলো "সুপারম্যান"।
সিস্টেম দেখলো, সে "সুপারম্যান" চেনে না।
কিন্তু সে "সুপার" চেনে, আর "ম্যান" চেনে।
সে ওটাকে ভেঙে ফেলবে: "সুপার" + "ম্যান"।
ব্যস, সে অর্থ আন্দাজ করে ফেললো।
বাংলায় "রাষ্ট্রপতি" শব্দটা সে হয়তো ভাঙবে "রাষ্ট্র" + "পতি" হিসেবে।
তখন সে "সেনাপতি" (সেনা + পতি) বা "দলপতি" (দল + পতি) দেখলেও ঘাবড়াবে না,
কারণ "পতি" ব্লকটা তার চেনা।
সুতরাং, টোকেনাইজেশন শুধু স্পেস দেখে শব্দ আলাদা করা নয়। এটা হলো একটা ভাষাকে তার মূল লেগো ব্লকগুলোতে ভেঙে ফেলার শিল্প।
এই ভাঙার কাজটা যত নিখুঁত হবে, কম্পিউটার তত ভালোভাবে আপনার ভাষা বুঝবে।
যদি ভাঙাটা ভুল হয়, তাহলে "নিউ ইয়র্ক" হয়ে যাবে "নতুন ইয়র্ক"। আর তখন গুগল আপনাকে "সেরা কাচ্চি" এর বদলে হয়তো "কাঁচা মরিচ" এর ছবি দেখাবে।
পরের বার যখন দেখবেন কোনো AI আপনার সাথে মানুষের মতো কথা বলছে, তখন মনে রাখবেন, এর সবকিছুর পেছনে প্রথম ধাপে রয়েছে এই নিরীহদর্শন "টোকেনাইজেশন" অর্থাৎ, শব্দ ভাঙার খেলা।